Component Jobs
Most operations, such as extracting data or running an application are executed in Keboola as background, asynchronous jobs. When an operation is triggered, for example, you run an extractor, a job is created. The job starts executing or waits in the queue until it can start executing. The job execution and queuing are fully automatic. The job execution is asynchronous, so you need to
- create (run) a job, and
- wait for it to finish.
The core API for working with jobs is the Queue API. It provides operations for running/creating, terminating and listing jobs. Components differ in their upper limits on how long a job can be executing and how much memory it is allowed to consume. These limits are set by the component developer and act primarily as a safeguard.
Job Properties
When you create a job it automatically transitions through states until it reaches some of the final states. When you create or retrieve a job, you’ll obtain a JSON with Job object, whose properties are described below in more detail.
Click to expand the response.
{
"id": "10440535",
"runId": "10440530.10440533.10440534.10440535",
"parentRunId": "10440530.10440533.10440534",
"project": {
"id": "66",
"name": "Sandbox"
},
"token": {
"id": "7455",
"description": "[_internal] Scheduler"
},
"status": "success",
"desiredStatus": "processing",
"mode": "run",
"component": "keboola.ex-db-snowflake",
"config": "493493",
"configData": [],
"configRowIds": [
"41510"
],
"tag": "5.5.0",
"createdTime": "2022-01-24T22:41:10+00:00",
"startTime": "2022-01-24T22:41:13+00:00",
"endTime": "2022-01-24T22:41:48+00:00",
"durationSeconds": 35,
"result": {
"input": {
"tables": []
},
"images": [
[
{
"id": "developer-portal-v2/keboola.ex-db-snowflake:5.5.0",
"digests": [
"developer-portal-v2/keboola.ex-db-snowflake@sha256:0f9428c52afea457ec3865cab7cfe457f4f875f3cf45d36f1876c709211da9cf"
]
}
]
],
"output": {
"tables": [
{
"id": "in.c-keboola-ex-db-snowflake-493493.opportunity",
"name": "opportunity",
"columns": [
{
"name": "Id"
},
{
"name": "Name"
},
{
"name": "AccountId"
},
{
"name": "OwnerId"
},
{
"name": "Amount"
},
{
"name": "StageName"
},
{
"name": "CreatedDate"
},
{
"name": "CloseDate"
},
{
"name": "Probability"
},
{
"name": "Start_Date"
},
{
"name": "End_Date"
},
{
"name": "Record_Type_Name"
},
{
"name": "AdvertiserName"
},
{
"name": "Advertiser_Vertical"
},
{
"name": "Type"
}
],
"displayName": "opportunity"
}
]
},
"message": "Component processing finished.",
"configVersion": "16"
},
"usageData": [],
"isFinished": true,
"url": "https://queue.north-europe.azure.keboola.com/jobs/10440535",
"branchId": null,
"variableValuesId": null,
"variableValuesData": {
"values": []
},
"backend": [],
"metrics": {
"backend": {
"size": null
},
"storage": {
"inputTablesBytesSum": 0
}
},
"behavior": {
"onError": null
},
"parallelism": "2",
"type": "standard"
}Job Status
A job can have different values for status:
created(the job is created, but has not started executing yet)waiting(the job is waiting for other jobs to finish)processing(job stuff is being done)success(the job is finished)error(the job is finished)warning(the job is finished, but one of its child jobs failed)terminating(the user has requested to abort the job)cancelled(the job was created, but it was aborted before its execution actually began)terminated(the job was created and it was aborted in the middle of its execution)
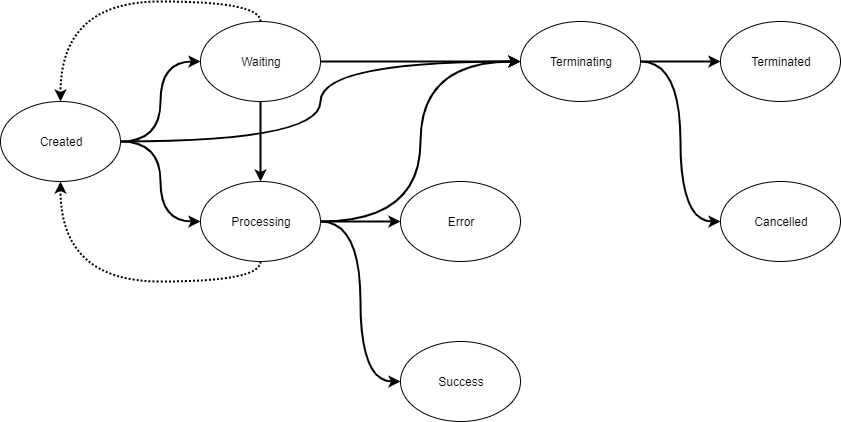
When you create a job it is in the created state. In a success scenario it will transition to a processing state and when the actual work is done, to the
success state. If you change your mind and terminate a job, it will enter terminating state and then ends with either terminated (execution terminated)
or cancelled (execution did not actually start). The difference is that you can be sure that a cancelled job did absolutely no operations,
whereas a terminated job, could’ve done even all of the work it was supposed to do.
If a job cannot be executed, it will enter the waiting state. The waiting state means that the job cannot be executed due to reasons on the Keboola
project side. This means that the reasons for waiting jobs lie solely in what jobs are already running in the given project. There are three core reasons for waiting jobs:
- If you run two jobs of the same configuration, the second one will wait until the first one is finished. This behavior is called “configuration lock” and protects your project from race conditions.
- Orchestration phases. When you run an orchestration, the jobs for all phases are created. Phases that depend on other phases enter the
waitingstate. - Setting parallel limits. If you run a configuration with 10 tables and set parallelism to 2, then 10 jobs will be created, 2 will enter
processingstate and 8 of them will immediately enter thewaitingstate.
If a job cannot be run due to platform reasons (e.g. insufficient resources, platform outage), it will remain in the created state. In rare situations
(e.g. hardware failure), the job may return back to created state. Moving the job out of the created state is out of the control of the end-user.
Of all the states a job can be in, only the state processing is considered to be job runtime (see durationSeconds field) and therefore billable.
That means waiting or created jobs do not have any costs associated with them, they represent a plan of what is going to happen.
The states terminated, cancelled, success and error are final and end the job transitions. When a job is in final state, the isFinished flag is true.
The job object is both immutable and eventually consistent. Once you create a job, you cannot change any of it’s properties. Any changing properties are
self-modifying and they will stop modifying once the job reaches one of the final states.
Apart from the status field, the job also has desiredStatus field. This is either processing or terminating. The desired status is
processing until a job termination is requested. This changes the desired status to terminating. Other changes are not permitted.
Job ID
When a job is created, an id and runId and optionally parentRunId are assigned to it. The runId and parentRunId represent
parent-child relationship between jobs. Parent-child hierarchical relationship can be defined via the X-KBC-RunId header, when used the
newly created job will become child of the job with the provided RunId.
The runId field contains job ids with representing the job hierarchy. If there is no hierarchy, then runId is equal to id. If there is
hierarchy then runId is parentId concatenated with id. The hierarchy delimiter is dot .. Examples:
id=123,runId=123,parentRunId=null– Job has no parentid=345,runId=123.345,parentRunId=123– Job is a child of job123.id=678,runId=123.345.678,parentRunId=123.345– Job is a child of job345which in turn is a child of job123.
Jobs may be nested without limits. The parent-child relationship itself is a weak relationship. By itself it does not mean anything special outside of UI grouping and the function that terminating a parent job issues a termination request to all its children. Running a job as a child of another job does not by itself cause the parent to wait for child completion or any other added functionality. Such functionality is implemented in specific components (e.g. Orchestrator) or for specific job types.
Job Configuration
To create a job, you must provide the configuration to run. A configuration is always tied to a specific component.
A configuration can be provided in multiple ways. The easiest is to provide a reference to
a stored configuration ID using the config field as shown above. Configurations can be stored and listed using the
Component Configurations API endpoint.
When using a configuration which contains Configuration Rows, the job can optionally execute
only certain rows. Use the configRowIds field to list row IDs to execute. Note that if you do not list any rows, then all rows will be executed except
for disabled rows. When you enumerate rows to execute, then the enumerated rows will be executed even if they are disabled. To run a job of
a configuration in a branch, provide the branch ID
in the branchId field. If you do not provide branchId, then the default branch is used.
Take care that only the combination of component ID, configuration ID and branch ID is unique. It is possible for two configurations with the
same ID to exist (either for different component or for a different branch).
Another option is to provide the entire configuration in the configData field. In that case the whole configuration data
has to be provided in the request. If you are retrieving a
stored configuration, take
note that the configuration data is the contents of the configuration node and not the entire
response. When using the configData field, the configRowIds and branchId values are ignored. When using the configData field the config field
is ignored for the purpose of reading the configuration, but may still be required in case the component is using
Default Bucket. In that case, the
configuration referenced in config is used to generate the name of the output bucket. It still holds that configuration data is not read from it.
That means that configData always fully overrides the config field.
Job Mode
When creating a job, you need to provide mode. This can be one of run, forceRun and debug. The basic mode choice is run.
Use the forceRun mode to run a configuration that is disabled. The debug can be used during Component Development & Debugging.
Job Runtime configuration
You may provide runtime settings for a job. Runtime settings do not affect what the job does, they affect how the job does it. The available runtime settings are:
backend.type— for Snowflake transformations this is the size of the Snowflake warehouse used for the job; otherwise it affects the container size. Available values for backend type aresmall,medium,large.parallelism— runs Configuration Rows (if present in the configuration) in parallel. Allowed values are integer values andinfinity, which runs all rows in parallel. When not specified, the rows are run sequentially.tag— runs the component with a specific version of code. This is mostly used during component development, testing and debugging.
Runtime parameters can be specified on various levels. The values can be specified in the component configuration. They can also be specified when creating a job, in which case it overrides the configuration. It may also be specified for an orchestration, in which case it overrides what is specified in individual jobs of that orchestration.
When stored in the component configuration, the runtime settings live in a top-level runtime node of the configuration JSON — a sibling of parameters,
not inside it. For example, to pin all jobs of a configuration to a specific image tag:
{
"parameters": {
"...": "..."
},
"runtime": {
"tag": "my-branch-3"
}
}Jobs of this configuration then run the given image tag (the job detail shows the resolved value in its tag field) until the runtime.tag key
is removed from the configuration. This is the usual way of testing a development build of a component in a single project without affecting
other projects — the tag in the Developer Portal stays untouched. Do not forget to remove the key when done; a pinned
configuration keeps running the old image even after new versions of the component are released.
Job Type
Job can be of one of the four types standard, container, phaseContainer and orchestrationContainer. The standard is something which does actual work.
Only standard jobs consume billable time and are counted towards consumption of any resources. Other job types are virtual containers encapsulating standard jobs.
The container job represent a job containing parallel executions
of configuration rows. phaseContainer type contains standard jobs in a single
phase of an orchestration. orchestrationContainer job type represents an orchestration and
contains phase jobs of that orchestration. What these job types have in common is a strong
parent-child relationship. This means for example that when a child job fails, the container fails too. The
behavior can be further controlled by the onError setting. You cannot specify job type when creating a job, it is selected automatically as needed.
Working with the Jobs API
The main API to run the jobs is Job Queue API. There are some API calls from other services which might be useful when working with jobs:
- Create configurations
- List Job Events
- Encrypt values
- Run Synchronous Actions
- Subscribe to Job Events
- Schedule jobs
The component jobs are asynchronous operations, this means that you create it and then you have to actively wait for the result. Note that there are other unrelated cases of asynchronous operations in Keboola Platform which are in principle the same, but may differ in little details. The most common one is: Storage Jobs, triggered, for instance, by asynchronous imports or exports
Run a Job
You need to know the component Id and configuration Id to create a job. You can get these from the UI links. To use the API to obtain a list of all components available in the project, and their configuration, you can use the Get components. See an example. A snippet of the response is below:
[
{
"id": "keboola.ex-db-snowflake",
"type": "extractor",
"name": "Snowflake",
"description": "Cloud-Native Elastic Data Warehouse Service",
"documentationUrl": "https://github.com/keboola/db-extractor-snowflake/blob/master/README.md",
"configurations": [
{
"id": "554424643",
"name": "Sample database",
"description": "",
"created": "2019-12-03T11:18:28+0100",
"creatorToken": {
"id": 199182,
"description": "ondrej.popelka@keboola.com"
},
"version": 3,
"changeDescription": "Quickstart config creation",
"isDisabled": false,
"isDeleted": false,
"currentVersion": {
"created": "2019-12-03T11:19:50+0100",
"creatorToken": {
"id": 199182,
"description": "ondrej.popelka@keboola.com"
},
"changeDescription": "Quickstart config creation"
}
}
]
}
]From there, the important part is the id field and configurations.id field. For instance, in the
above, there is a database extractor with the id keboola.ex-db-snowflake and a
configuration with the id 554424643.
Then use the create a job API call and pass the configuration ID and component ID in request body:
{
"component": "keboola.ex-db-snowflake",
"config": "554424643",
"mode": "run"
}
See an example. When a job is created, you will obtain a response similar to this:
{
"id": "807932655",
"runId": "807932655",
"parentRunId": "",
"project": {
"id": "7150",
"name": "Sandbox"
},
"token": {
"id": "199182",
"description": "ondrej.popelka@keboola.com"
},
"status": "created",
"desiredStatus": "processing",
"mode": "run",
"component": "keboola.ex-db-snowflake",
"config": "554424643",
"configData": [],
"configRowIds": [],
"tag": "5.5.0",
"createdTime": "2022-01-25T16:34:40+00:00",
"startTime": null,
"endTime": null,
"durationSeconds": 0,
"result": [],
"usageData": [],
"isFinished": false,
"url": "https://queue.keboola.com/jobs/807932655",
"branchId": null,
"variableValuesId": null,
"variableValuesData": {
"values": []
},
"backend": [],
"metrics": [],
"behavior": {
"onError": null
},
"parallelism": null,
"type": "standard"
}
This means that the job was created and will automatically start executing.
From the above response, the most important part is url, which gives you the URL of the resource for
Job status polling.
Job Polling
If you want to get the actual job result, poll the Job API for the current state of the job. See an example.
You will receive a response in the same format as when you crated the job:
{
"id": "807933826",
"runId": "807933826",
"parentRunId": "",
"project": {
"id": "7150",
"name": "7150"
},
"token": {
"id": "199182",
"description": "ondrej.popelka@keboola.com"
},
"status": "processing",
"desiredStatus": "processing",
"mode": "run",
"component": "keboola.ex-db-snowflake",
"config": "554424643",
"configData": [],
"configRowIds": [],
"tag": "5.5.0",
"createdTime": "2022-01-25T16:41:12+00:00",
"startTime": "2022-01-25T16:41:22+00:00",
"endTime": null,
"durationSeconds": 0,
"result": [],
"usageData": [],
"isFinished": false,
"url": "https://queue.keboola.com/jobs/807933826",
"branchId": null,
"variableValuesId": null,
"variableValuesData": {
"values": []
},
"backend": [],
"metrics": [],
"behavior": {
"onError": null
},
"parallelism": null,
"type": "standard"
}
From the above response, the most important part is the status field (processing, in this case).
To obtain the Job result, periodically send the above API call until the job status changes
to one of the finished states or until isFinished is true.
Run a Debug job
To run a debug job, use debug for the mode. Optionally you can provide the component version which should run
to live test an image.
{
"component": "keboola.ex-db-snowflake",
"config": "554424643",
"mode": "debug",
"tag": "5.5.0"
}
The debug mode creates a job that prepares the data folder including the serialized configuration files. Then it compresses the data folder and uploads it to your project’s Files in Storage. This way you will get a snapshot of what the data folder looked like before the component started. If processors are used, a snapshot of the data folder is created before each processor. After the entire component finishes, another snapshot is made. For example, if you run component A with processor B and C in the after section, you will receive:
stage_0file with contents of the data folder before component A was runstage_1file with contents of the data folder before processor B was runstage_2file with contents of the data folder before processor C was runstage_outputfile with contents of the data folder before output mapping was about to be performed (after C finished).
If configuration rows are used, then the above is repeated for each configuration row. If the job finishes with and error, only the stages before the error are uploaded.
This API call does not upload any tables or files to Storage. I.e. when the component finishes, its output is discarded and the output mapping to storage is not performed. This makes this API call generally very safe to call, because it cannot break the Keboola project in any way. However, keep in mind, that if the component has any outside side effects, these will get executed. This applies typically to writers which will write the data into the external system even when running in debug mode.
Note that the snapshot archive will contain all files in the data folder including any temporary files produced be the component. The snapshot will not contain the output state.json file. This is because the snapshot is made before a component is run where the out state of the previous component is not available any more. Also note that all encrypted values are removed from the configuration file and there is no way to retrieve them. It is also advisable to run this command with limited input mapping so that you don’t end up with gigabyte size archives.