Functions
Functions are simple pre-defined functions that
- allow you to add extra flexibility when needed.
- can be used in several places in the Generic Extractor configuration to introduce dynamically generated values instead of those provided statically.
- allow referencing the existing values in the configuration instead of copying them.
- are advantageous and sometimes necessary when publishing your configuration as a new component.
Configuration
A function is used instead of a simple value in specific parts of the Generic Extractor configuration (see below).
A function configuration is an object with the properties function (one of the available function names and args
(function arguments), for example:
{
"function": "concat",
"args": [
"John",
"Doe"
]
}The argument of a function can be any of the following:
- Scalar (simple) value (as in the above example)
- Reference to a value from function context (see below)
- Another function object
Additionally, the function may be replaced by a plain reference to the function context. This means you can write (where permitted) a configuration value in three possible ways:
A simple value:
{
...,
"baseUrl": "http://example.com/
}A function call:
{
...,
"baseUrl": {
"function": "concat",
"args": [
"http://",
"example.com"
]
}
}A reference to a value from the function context:
{
...,
"baseUrl": {
"attr": "someUrl"
}
}These forms can be combined freely. They can be also nested in a virtually unlimited way. For instance:
{
...,
"baseUrl": {
"function": "concat",
"args": [
"https://",
{
"attr": "domain"
}
]
}
}User Interface
You may create functions in the user interface’s User Parameters or User Data sections.
You can also create the functions directly from other configuration contexts, e.g., when defining the query parameters on the endpoint.
Aside from predefined functions, the UI also offers the most common templates that you can use.
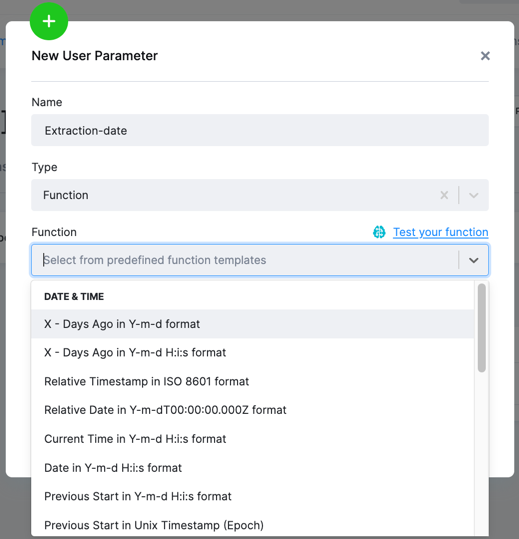
The UI also offers a convenient way to evaluate the function and see the results.
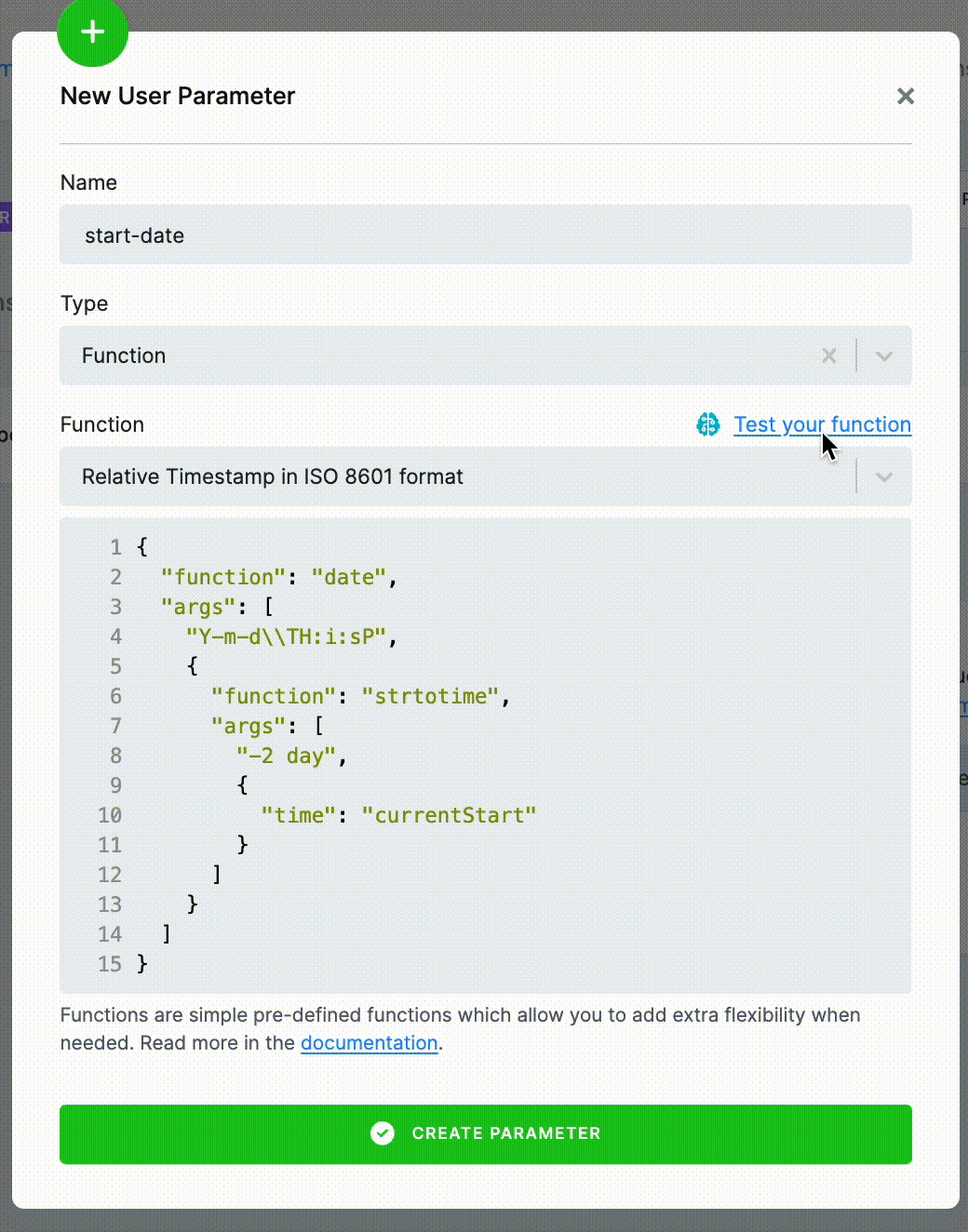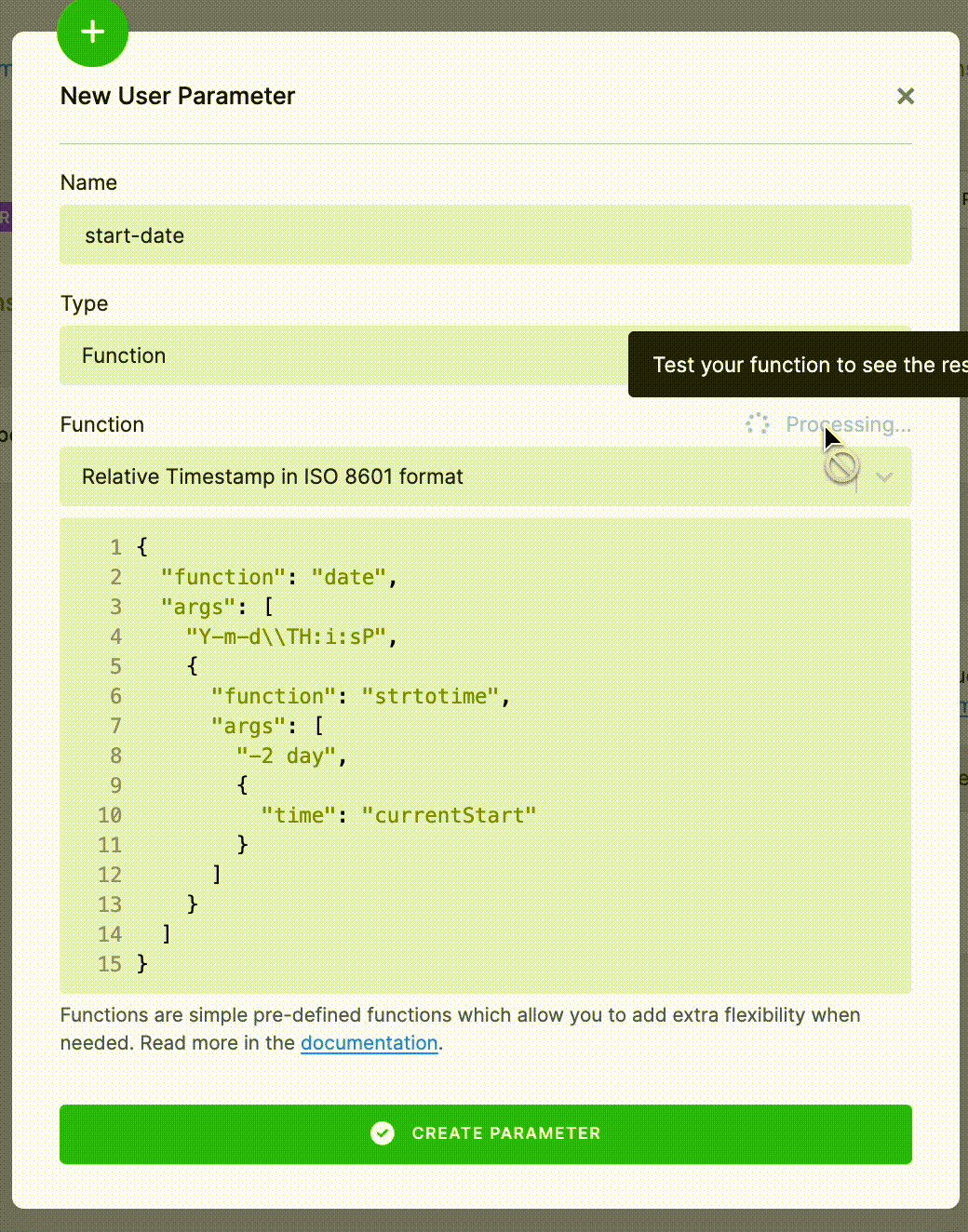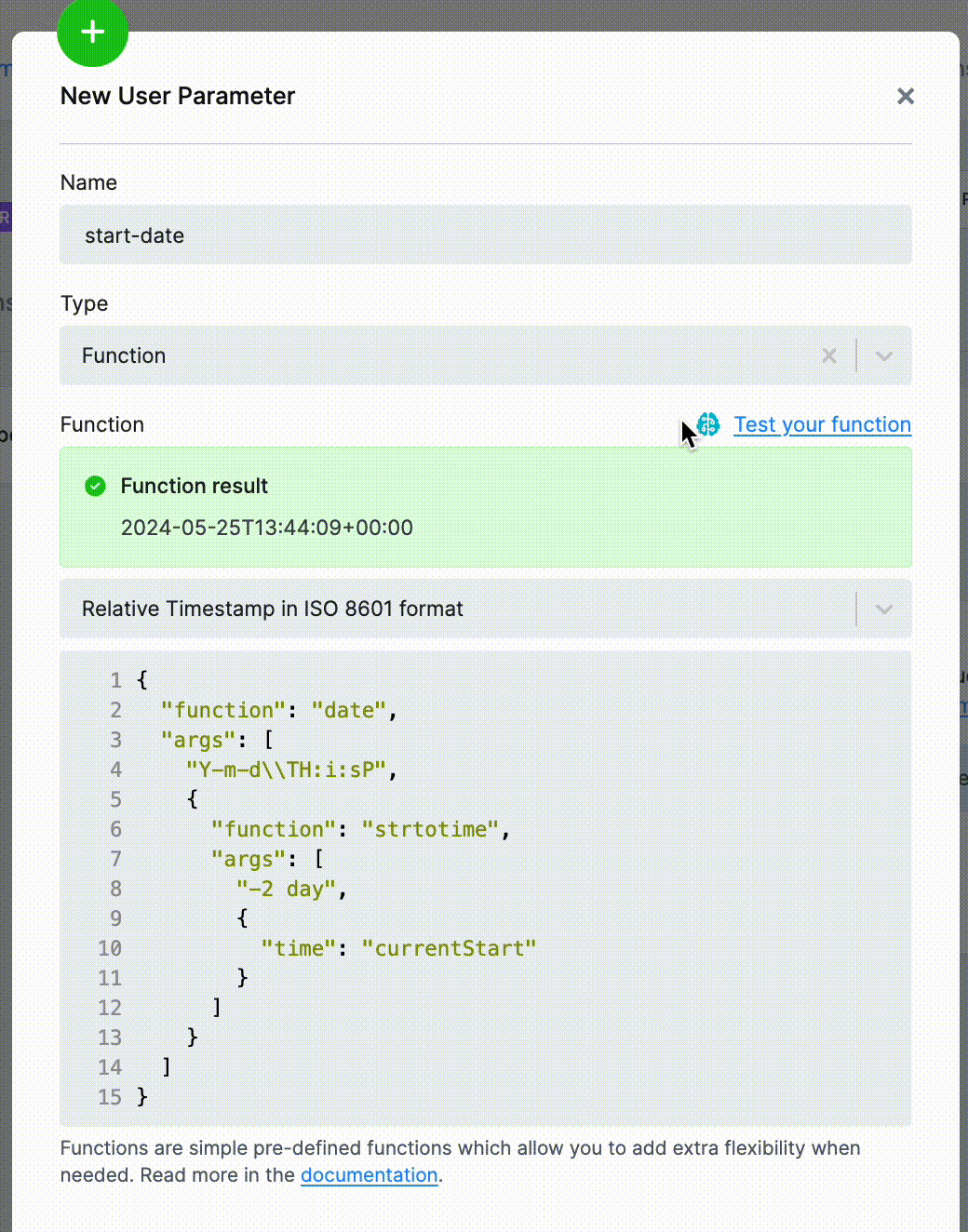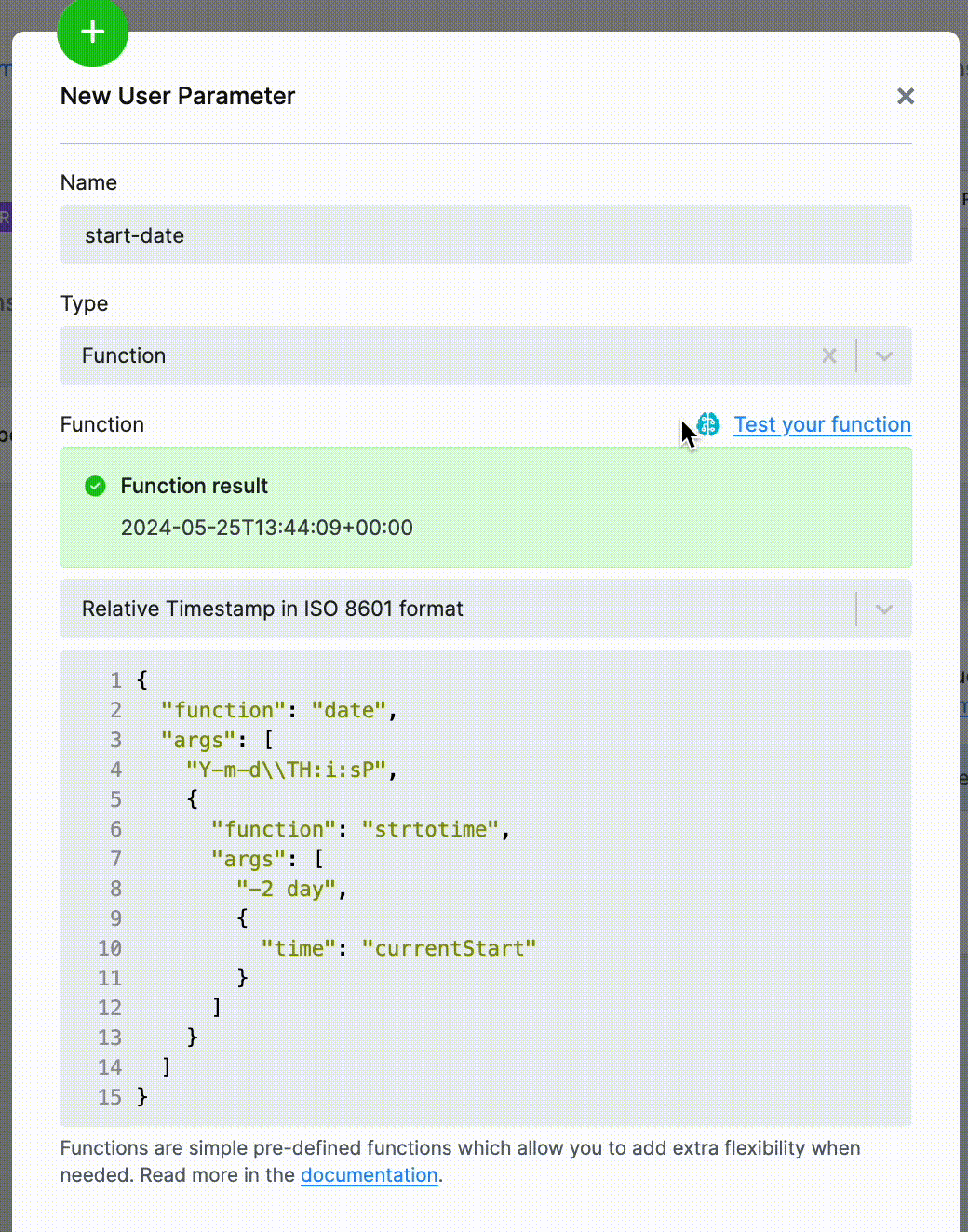
Supported Functions
md5
The md5 function calculates the MD5 hash of a
string. The function takes one argument, which is the string to hash.
{
"function": "md5",
"args": [
"NotSoSecret"
]
}The above will produce 1228d3ff5089f27721f1e0403ad86e73.
See an example.
sha1
The sha1 function calculates the SHA-1 hash of a
string. The function takes one argument which is the string to hash.
{
"function": "sha1",
"args": [
"NotSoSecret"
]
}The above will produce 64d5d2977cc2573afbd187ff5e71d1529fd7f6d8.
See an example.
base64_encode
The base64_encode function converts a
string to the MIME Base64 encoding. The function
takes one argument which is the string to encode.
{
"function": "base64_encode",
"args": [
"TeaPot"
]
}The above will produce VGVhUG90.
See an example.
hash_hmac
The hash_hmac function creates
an HMAC (Hash-based message authentication code)
from a string. The function takes
three arguments:
- Name of a hashing algorithm (see the list of supported algorithms)
- Value to hash
- Secret key
{
"function": "hash_hmac",
"args": [
"sha256",
"12345abcd5678efgh90ijk",
"TeaPot"
]
}The above will return d868d581b2f2edd09e8e7ce12c00723b3fcffb6a5d74c40eae9d94181a0bf731.
See an example.
hash
This function works similarly to the hash_hmac function but requires only two arguments (no secret key required):
- The name of a hashing algorithm (see the list of supported algorithms).
- The value to hash.
{
"function": "hash",
"args": [
"sha256",
"12345abcd5678efgh90ijk"
]
}time
The time function returns the current time as a
Unix timestamp.
To obtain the current time in a more readable format, use the
the date function. It takes no arguments.
{
"function": "time"
}The above will produce something like 1492674974.
date
The date function formats the provided or the current
timestamp into a human readable format. The function takes either one or two arguments:
- Formatting string
- Optional Unix timestamp; if not provided, the current time is used.
{
"function": "date",
"args": [
"Y-m-d"
]
}The above will produce something like 2017-04-20.
{
"function": "date",
"args": [
"Y-m-d H:i:s",
1490000000
]
}The above will produce 2017-03-20 8:53:20.
See an example.
strtotime
The strtotime function converts a string date into a Unix timestamp. The function takes
one or two arguments:
- String date
- Base for relative dates (see below)
{
"function": "strtotime",
"args": [
"21 oct 2017 9:16pm"
]
}The above will produce 1508620560, which represents the date 2017-10-21 21:16:00. However, the
strtotime function is most useful with relative dates which it also allows. For example, you can
write:
{
"function": "strtotime",
"args": [
"-7 days",
1508620560
]
}The above will give 1508015760, which represents the date 2017-10-14 21:16:00. The second argument
specifies the base date (as a Unix timestamp) from which the relative date is computed. This is particularly
useful for incremental extraction. Also note that
it is common to combine the strtotime and date functions to convert between string and timestamp
representation of a date.
See an example.
sprintf
The sprintf function formats values and inserts them into a string. The sprintf function maps directly to
the original PHP function, which is very versatile and has many
uses. The function accepts two or more arguments:
- String with formatting directives (marked with the percent character
%) - Values inserted into the string:
{
"function": "sprintf",
"args": [
"Three %s are %.2f %s.",
"apples",
0.5,
"plums"
]
}The above will produce Three apples are 0.50 plums.
See a simple insert example or a formatting example.
concat
The concat function concatenates an arbitrary number of strings into one. For example:
{
"function": "concat",
"args": [
"Hen",
"Or",
"Egg"
]
}The above will produce HenOrEgg (see example 1, example 2). See also the
implode function.
implode
The implode function concatenates an arbitrary number
of strings into one using a delimiter. The function takes
two arguments:
- Delimiter string which is used for the concatenation
- Array of values to be concatenated
For example:
{
"function": "implode",
"args": [
",",
[
"apples",
"oranges",
"plums"
]
]
}The above will produce apples,oranges,plums (see an example).
The delimiter can be empty, in which case the implode function is equivalent to the concat function:
{
"function": "implode",
"args": [
"",
[
"Hen",
"Or",
"Egg"
]
]
}ifempty
The ifempty function can be useful for handling optional values. The function takes two arguments and
returns the first one if it is not empty. If the first argument is empty, it returns the second argument.
{
"function": "ifempty",
"args": [
"",
"Banzai"
]
}The above will return Banzai. For the ifempty function, an empty string and the values 0 and null are
considered ‘empty’.
See an example.
Function Contexts
Every place in the Generic Extractor configuration in which a function may be used may allow different arguments of the function. This is referred to as a function context. Many contexts share access to configuration attributes.
Configuration Attributes
The configuration attributes are accessible in specific function contexts and they represent the entire config
section of the Generic Extractor configuration. There is some processing involved:
- The
jobssection is removed entirely. - All other values are flattened (keys are concatenated using a dot
.) into a one-level deep object. - The result object is available in a property named
attr.
For example, the following configuration:
{
"parameters": {
"api": {
"baseUrl": "http://example.com"
},
"config": {
"debug": true,
"outputBucket": "get-tutorial",
"server": "localhost:8888",
"incrementalOutput": false,
"jobs": [
{
"endpoint": "users",
"dataType": "users"
}
],
"http": {
"headers": {
"X-AppKey": "ThisIsSecret",
"X-Auth": {
"function": "concat",
"args": [
"Tea",
"Pot"
]
}
}
},
"userData": {
"tag": "fullExtract",
"mode": "development"
},
"mappings": {
"content": {
"whatever": "foobar"
}
}
}
}
}will be converted to the following function context:
{
"attr": {
"debug": true,
"outputBucket": "mock-server",
"server": "localhost:8888",
"incrementalOutput": false,
"http.headers.X-AppKey": "ThisIsSecret",
"http.headers.X-Auth.function": "concat",
"http.headers.X-Auth.args.0": "Tea",
"http.headers.X-Auth.args.1": "Pot",
"userData.tag": "fullExtract",
"userData.mode": "development",
"mappings.content.whatever": "foobar"
}
}See example [EX119].
Base URL Context
The Base URL function context is used when setting the baseURL for API, and it
contains configuration attributes.
See an example.
Headers Context
The Headers function context is used when setting the http.headers for API
or the http.headers in config, and it contains
configuration attributes.
See an example.
Parameters Context
The Parameters function context is used when setting job request parameters — params.
It contains configuration attributes plus the times of the current
(currentStart) and previous (previousStart) run of Generic Extractor.
The times are Unix timestamps.
If the extraction is run for the first time, previousStart is 0.
With the following configuration:
{
"parameters": {
"api": {
"baseUrl": "http://example.com"
},
"config": {
"debug": true,
"outputBucket": "get-tutorial",
"server": "localhost:8888",
"jobs": [
...
]
}
}
}the parameters function context will contain:
{
"attr": {
"debug": true,
"outputBucket": "mock-server",
"server": "localhost:8888"
},
"time": {
"previousStart": 0,
"currentStart": 1492678268
}
}See an example of using parameters context.
The time values are used in incremental processing.
Placeholder Context
The Placeholder function context refers to configuration of placeholders in child jobs.
When using function to process a placeholder value, the placeholder must be specified as an object with the path property.
Therefore instead of writing:
"placeholders": {
"user-id": "userId"
}write:
"placeholders": {
"user-id": {
"path": "userId",
"function": ...
}
}The placeholder function context contains the following structure:
{
"placeholder": {
"value": "???"
}
}where ??? is the value obtained from the response JSON from the path provided in the path property
of the placeholder.
See an example.
User Data Context
The User Data function context is used when setting the userData.
The parameters context contains configuration attributes plus the times of the current (currentStart) and
previous (previousStart) run of Generic Extractor. The User Data Context is therefore
same as the Parameters Context.
See an example.
Login Authentication Context
The Login Authentication function context is used in the
login authentication method.
Functions are supported in both loginRequest
and apiRequest configurations.
The loginRequest function context contains configuration attributes.
In the apiRequest context, the flattened reponse of the login request is available additionally
to the configuration attributes.
The login authentication context is the same for both params and headers
login authentication configuration options. If the
login authentication request returns e.g.:
{
"user": "John Doe",
"authorization": {
"token": "quiteSecret",
"validUntil": "2017-20-12 12:20:17"
}
}The following function context will be available in the API request headers and query:
{
"attr": {
"outputBucket": "mock-server"
},
"response": {
"user": "John Doe",
"authorization.token": "quiteSecret",
"authorization.validUntil": "2017-20-12 12:20:17"
}
}The login response is available in the response node. The attr node contains configuration attributes.
See an example and a more
complicated example of using functions in
both login request and API request.
Query Authentication Context
The Query Authentication function context is used in the
query authentication method.
The Query Authentication Context contains configuration attributes plus
a representation of the complete HTTP request to be sent (request) plus a key
value list of query parameters of the HTTP request (query).
The following configuration:
{
"parameters": {
"api": {
"baseUrl": "http://example.com/",
"http": {
"defaultOptions": {
"params": {
"account": "admin"
}
}
},
"authentication": {
"type": "query",
"query": {
"signature": {
"function": "sha1",
"args": [
"time",
{
"attr": "#api-key"
}
]
}
}
}
},
"config": {
"#api-key": "12345abcd5678efgh90ijk",
"outputBucket": "mock-server",
"jobs": [
{
"endpoint": "users",
"params": {
"showColumns": "all"
}
}
]
}
}
}leads to the following function context:
{
"query": {
"account": "admin",
"showColumns": "all"
},
"request": {
"url": "http:\/\/example.com\/users?account=admin&showColumns=all",
"path": "\/users",
"queryString": "account=admin&showColumns=all",
"method": "GET",
"hostname": "example.com",
"port": 80,
"resource": "\/users?account=admin&showColumns=all"
},
"attr": {
"#api-key": "12345abcd5678efgh90ijk",
"outputBucket": "mock-server"
}
}See the basic example and a more complicated example.
OAuth 2.0 Authentication Context
The OAuth Authentication Context is used for the
oauth20 authentication method
(it is not applicable to oauth10) and contains the following:
- Representation of the complete HTTP request to be sent (
request) - A key value list of query parameters of the HTTP request (
query) - An
authorizationsection containing the response from the OAuth service provider
This context is available for both the headers and query sections of the oauth20 authentication methods.
The following configuration:
{
"parameters": {
"api": {
"baseUrl": "http://example.com/",
"authentication": {
"type": "oauth20",
"format": "json",
"headers": {
"Authorization": {
"function": "concat",
"args": [
"Bearer ",
{
"authorization": "#data.access_token"
}
]
}
}
}
},
"config": {
"outputBucket": "mock-server",
"jobs": [
{
"endpoint": "users",
"dataType": "users"
}
]
}
},
"authorization": {
"oauth_api": {
"credentials": {
"#data": "{\"status\": \"ok\",\"access_token\": \"testToken\", \"foo\": {\"bar\": \"baz\"}}",
"appKey": "clientId",
"#appSecret": "clientSecret"
}
}
}
}leads to the following function context:
{
"query": {
"showColumns": "all"
},
"request": {
"url": "http:\/\/example.com\/users?showColumns=all",
"path": "\/users",
"queryString": "showColumns=all",
"method": "GET",
"hostname": "example.com",
"port": 80,
"resource": "\/users?showColumns=all"
},
"authorization": {
"data.status": "ok",
"data.access_token": "testToken",
"data.foo.bar": "baz"
"timestamp": 1492949837,
"nonce": "99206d94a6846841",
"clientId": "clientId",
}
}The authorization section of the configuration contains the
OAuth2 response. The function context contains
the parsed and flattened response fields under the key data, provided that the response was sent in JSON format
and that "format": "json" was set.
In the response above, these are the keys data.status, data.access_token, data.foo.bar. This is defined
entirely by the behavior of the OAuth Service provider. If the response is a plaintext (usually directly a token),
then the entire response is available in the field data.
Apart from that, the fields timestamp (Unix timestamp of the request),
nonce (cryptographic nonce for
signing the request) and clientId (the value of authorization.oauth_api.credentials.appKey, which is obtained when
the application is published) are added to the authorization section.
For usage, see OAuth examples.
OAuth 2.0 Login Authentication Context
The OAuth Login Authentication Context is used for the
oauth20.login authentication method
(it is not applicable to oauth20). The OAuth Login Authentication context contains
OAuth information split into the properties consumer (response obtained from the service provider) and
user (data obtained from the user). This context is available for
both the headers and params sections of the oauth20 authentication methods.
For the context available in the apiRequest configuration, see the login authentication.
The following configuration:
{
"parameters": {
"api": {
"baseUrl": "http://example.com",
"authentication": {
"type": "oauth20.login",
...
}
},
"config": {
...
}
},
"authorization": {
"oauth_api": {
"credentials": {
"#data": "{\"status\": \"ok\",\"access_token\": \"testToken\", \"mac_secret\": \"iAreSoSecret123\", \"foo\": {\"bar\": \"baz\"}}",
"appKey": "clientId",
"#appSecret": "clientSecret"
}
}
}
}leads to the following function context:
{
"consumer": {
"client_id": "clientId",
"client_secret": "clientSecret"
},
"user": {
"status": "ok",
"access_token": "testToken",
"mac_secret": "iAreSoSecret123",
"foo.bar": "baz"
}
}The authorization section of the configuration contains the
OAuth2 response. The function context
contains the parsed and flattened response fields in the user property. The content of the
user property is fully dependent on the response of the OAuth service provider. The
consumer property contains the client_id and client_secret which contain values of
authorization.oauth_api.credetials.appKey and
authorization.oauth_api.credetials.appSecret respectively.
(These are obtained by Keboola when the application is published).
For usage, see OAuth Login examples.
Examples
API Base URL
When publishing your Generic Extractor configuration, chances are
you want the end-user to provide a part of the API configuration. Due to the limitations of
how templates work, the parameter
obtained from the end-user configuration will be only available in the config section.
Let’s say that the end-user enters www.example.com as the API server and that values become
available as the server property of the config section, for instance:
"config": {
"outputBucket": "ge-tutorial",
"server": "www.example.com",
"jobs": [
{
"endpoint": "users",
"dataType": "users"
}
]
}This means that the configuration attributes will be available as:
{
"attr": {
"outputBucket": "ge-tutorial",
"server": "www.example.com"
}
}Then use the concat function to access that value and merge it with other parts to create the
final API URL (http://example.com/api/1.0/):
{
"parameters": {
"api": {
"baseUrl": {
"function": "concat",
"args": [
"http://",
{
"attr": "server"
},
"/api/1.0/"
]
}
}
}
}See example [EX087] with concat or an alternative example [EX088] with sprintf.
API Default Parameters
Suppose you have an API which expects a tokenHash parameter to be sent with every request. The
token hash is supposed to be generated by the SHA-256 hashing algorithm from a token and secret
you obtain.
Because the api.http.defaultOptions.params option does not
support functions, either supply the parameters in the jobs.params
configuration, or use API Query Authentication.
Using (or abusing) the API Query Authentication is possible if the default parameters represent authentication, or
if the API does not use any authentication method (two authentication methods are not possible):
The below configuration reads the #api-key and #secret-key parameters from the config section,
computes SHA-256 hash and sends it as a tokenHash parameter with every request.
{
"parameters": {
"api": {
"baseUrl": "http://example.com/",
"authentication": {
"type": "query",
"query": {
"tokenHash": {
"function": "hash_hmac",
"args": [
"sha256",
{
"attr": "#api-key"
},
{
"attr": "#secret-key"
}
]
}
}
}
},
"config": {
"#api-key": "12345abcd5678efgh90ijk",
"#secret-key": "TeaPot",
"debug": true,
"outputBucket": "mock-server",
"jobs": [
{
"endpoint": "users",
"dataType": "users"
}
]
}
}
}See example [EX099].
The solution with using the jobs.params configuration can look like this:
{
"parameters": {
"api": {
"baseUrl": "http://example.com/"
},
"config": {
"#api-key": "12345abcd5678efgh90ijk",
"#secret-key": "TeaPot",
"debug": true,
"outputBucket": "mock-server",
"jobs": [
{
"endpoint": "users",
"dataType": "users",
"params": {
"tokenHash": {
"function": "hash_hmac",
"args": [
"sha256",
{
"attr": "#api-key"
},
{
"attr": "#secret-key"
}
]
}
}
}
]
}
}
}The only practical difference is that the tokenHash parameter is going to be sent only with
the single users job.
See example [EX098].
API Query Authentication
Suppose you have an API with only a single endpoint /items to which you have to
pass a type parameter to list resources of a given type. On top of that, the API requires
an apiToken parameter and a signature parameter (a hash of the token and type) to be sent with every request.
The following configuration handles the situation:
{
"parameters": {
"api": {
"baseUrl": "http://mock-server:80/101-function-query-auth/",
"authentication": {
"type": "query",
"query": {
"apiToken": {
"attr": "#token"
},
"signature": {
"function": "sha1",
"args": [
{
"function": "concat",
"args": [
{
"attr": "#token"
},
{
"query": "type"
}
]
}
]
}
},
"apiRequest": {
"headers": {
"X-Api-Token": "token"
}
}
}
},
"config": {
"#token": "1234abcd567efg890hij",
"debug": true,
"outputBucket": "mock-server",
"jobs": [
{
"endpoint": "items",
"dataType": "users",
"params": {
"type": "users"
}
},
{
"endpoint": "items",
"dataType": "orders",
"params": {
"type": "orders"
}
}
]
}
}
}There are two jobs, both to the same endpoint (items), but with a different type parameter and dataType.
The authentication method query adds two more parameters to each request: apiToken (contain the value
of config.#token) and signature. The signature parameter is created as an SHA-1 hash of the
token and resource type ("query": "type" is taken from the jobs.params.type value).
See example [EX101].
Job Placeholders
Let’s say you have an API with an endpoint /users, returning a list of users, and an
endpoint /user/{userId}, returning details of a specific user with a given ID. The list response
looks like this:
[
{
"id": 3,
"name": "John Doe"
},
{
"id": 234,
"name": "Jane Doe"
}
]To obtain the details of the first user, the user-id has to be padded to five digits. The details API call for the
first user must be sent to /user/00003, and for the second user to /user/00234. To achieve this, use the
sprintf function, which allows number padding.
The following placeholders configuration in the child job calls the function with the first argument set to
%'.05d (which is a sprintf format to pad with zero to five digits)
and the second argument set to the value of the id property found in the parent response. The placeholder path must
be specified in the path property. That means that the configuration:
"placeholders": {
"user-id": "id"
}has to be converted to:
"placeholders": {
"user-id": {
"path": "id",
"function": "sprintf",
"args": [
"%'.05d",
{
"placeholder": "value"
}
]
}
}The following user-detail table will be extracted:
| id | name | address_city | address_country | address_street | parent_id |
| 123 | John Doe | London | UK | Whitehaven Mansions | 00003 |
| 234 | Jane Doe | St Mary Mead | UK | High Street | 00234 |
Notice that the parent_id column contains the processed value and not the original one.
See example [EX085], or a not-so-useful example [EX086] (using reference).
Job Parameters
Let’s say you have an API which requires you to send a hash of a certain value with every request. Specifically, each request must be done with the HTTP POST method with content:
{
"token": "someValue"
}The following configuration does exactly that. The value of the token is taken from the configuration
root (using the attr reference). This is useful in case the configuration is used as part of a
template. The actual hash will be generated of the NotSoSecret value.
{
"parameters": {
"api": {
"baseUrl": "http://example.com/"
},
"config": {
"debug": true,
"outputBucket": "mock-server",
"tokenValue": "NotSoSecret",
"jobs": [
{
"endpoint": "users",
"dataType": "users",
"method": "POST",
"params": {
"token": {
"function": "md5",
"args": [
{
"attr": "tokenValue"
}
]
}
}
}
]
}
}
}See example [EX089] or an alternative example [EX090] with SHA1 hash. or an alternative example [EX136] with more deeply nested functions.
Optional Job Parameters
Let’s say you have an API which allows you to send the list of columns to be contained in the API response.
For example, to list users and include their id, name and login properties, call
/users?showColumns=id,name,login. Also, you want to enter these values as an array in the config section because
the config is generated by a template. If the end-user
does not wish to filter the columns, they can
list all the columns (which would be annoying) or leave the column filter empty. In that case, the API
call would be /users?showColumns=all.
The following configuration does exactly that:
{
"parameters": {
"api": {
"baseUrl": "http://example.com/"
},
"config": {
"columns": "",
"outputBucket": "mock-server",
"jobs": [
{
"endpoint": "users",
"dataType": "users",
"method": "GET",
"params": {
"showColumns": {
"function": "ifempty",
"args": [
{
"attr": "columns"
},
"all"
]
}
}
}
]
}
}
}See example [EX097].
User Data
Assume that you have an API returning a response that does not contain any time information. For example:
[
{
"id": 3,
"name": "John Doe"
},
{
"id": 234,
"name": "Jane Doe"
}
]Add the extraction time to each record so that you at least know when each record was obtained
(when the creation time is unknown). Add additional data to each record using
the userData configuration:
"userData": {
"extractionDate": {
"function": "date",
"args": [
"Y-m-d H:i:s",
{
"time": "currentStart"
}
]
}
}The following table will be extracted:
| id | name | extractionDate |
| 3 | John Doe | 2017-04-20 10:17:20 |
| 234 | Jane Doe | 2017-04-20 10:17:20 |
Or, use an alternative configuration that also adds the current date:
"userData": {
"extractionDate": {
"function": "date",
"args": [
"Y-m-d H:i:s"
]
}
}But whereas the first one puts a single same date to each record, the alternative configuration will return different times for different records as they are extracted.
See example [EX091] or an alternative example [EX092] with a set date.
Headers
Suppose you have an API which requires you to send a custom X-Api-Auth header with every request.
The header must contain a user name and password separated by a colon. For instance, JohnDoe:TopSecret.
This can be done using the following api configuration:
"api": {
"baseUrl": "http://example.com/",
"http": {
"headers": {
"X-Api-Auth": {
"function": "concat",
"args": [
{
"attr": "credentials.#username"
},
":",
{
"attr": "credentials.#password"
}
]
}
}
}
}Alternatively, achieve the same result using the implode function:
"api": {
"baseUrl": "http://mock-server:80/093-function-api-http-headers/",
"http": {
"headers": {
"X-Api-Auth": {
"function": "implode",
"args": [
":",
[
{
"attr": "credentials.#username"
},
{
"attr": "credentials.#password"
}
]
]
}
}
}
}Both configurations rely on having the username and password parameters
in the config section, in this case also nested in the credentials property:
"config": {
"credentials": {
"#username": "JohnDoe",
"#password": "TopSecret"
},
"jobs": ...
}See example [EX093] or an
alternative example [EX094] setting headers in the config section.
Nested Functions
If the API in the above example tries to mimic the
HTTP authentication,
the header has to be sent as a base64 encoded value.
That is instead of sending a JohnDoe:TopSecret, you have to send Sm9obkRvZTpUb3BTZWNyZXQ=. To do this
you have to wrap the concat function which generates the header value in another function (base64_encode).
"api": {
"baseUrl": "http://example.com/",
"http": {
"headers": {
"X-Api-Auth": {
"function": "base64_encode",
"args": [
{
"function": "concat",
"args": [
{
"attr": "#username"
},
":",
{
"attr": "#password"
}
]
}
]
}
}
}
}See example [EX095].
Nested StrToTime
Suppose you have an API which requires you to specify the from and to date parameters to obtain orders created
in that time interval. You want to specify only the from date and extract a week of data.
Enter (preferably in a template) the
value 2017-10-04 and send an API request to
/orders?from=2017-10-04&to=2017-10-11. The following configuration can be used:
{
"parameters": {
"api": {
"baseUrl": "http://example.com/"
},
"config": {
"startDate": "2017-10-04",
"outputBucket": "mock-server",
"jobs": [
{
"endpoint": "users",
"dataType": "users",
"method": "GET",
"params": {
"from": {
"attr": "startDate"
},
"to": {
"function": "date",
"args": [
"Y-m-d",
{
"function": "strtotime",
"args": [
"+7 days",
{
"function": "strtotime",
"args": [
{
"attr": "startDate"
}
]
}
]
}
]
}
}
}
]
}
}
}The configuration probably seems rather complicated, so taken apart – the most innermost part:
{
"function": "strtotime",
"args": [
{
"attr": "startDate"
}
]
}takes the value from the config property startDate (which is 2017-10-04) and converts it to
a timestamp value (??? below).
Then there is an outer part:
{
"function": "strtotime",
"args": [
"+7 days",
???
]
}that takes the timestamp representing 2017-10-04 and adds 7 days to it. This yields another
timestamp value (??? below).
Then there is another outer part:
{
"function": "date",
"args": [
"Y-m-d",
???
]
}converting the timestamp back to a string format (Y-m-d format) which yields 2017-10-11.
This value is assigned to the to parameter of the API call.
See example [EX096].