Jobs Tutorial
On your way through the Generic Extractor tutorial, you have learned about
Now, we will show you how to use Generic Extractor’s sub-jobs.
Let’s start this section with a closer examination of the campaigns resource of the MailChimp API.
Besides retrieving multiple campaigns using the /campaigns endpoint, it can also retrieve detailed
information about a single campaign using /campaigns/{campaign_id}.
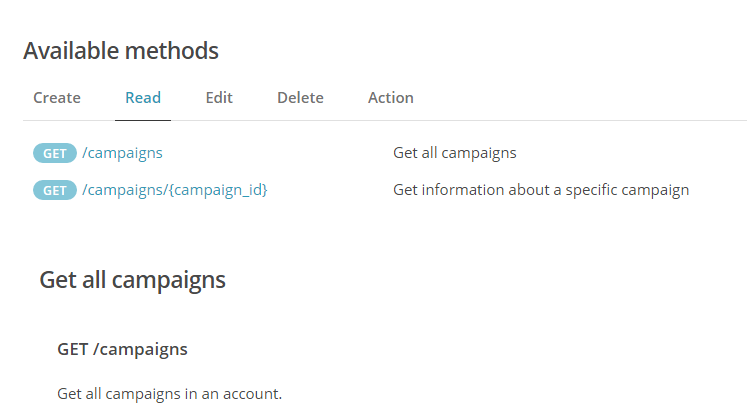
Moreover, each campaign has three sub-resources:
/campaigns/{campaign_id}/content, /campaigns/{campaign_id}/feedback
and /campaigns/{campaign_id}/send-checklist. The {campaign_id} expression represents a placeholder
that a specific campaign ID should replace. To retrieve the sub-resource, use child jobs.
Child Jobs
In the previous part of the tutorial, you created this job property in the Generic Extractor configuration:
"jobs": [
{
"endpoint": "campaigns",
"dataField": "campaigns"
}
]All sub-resources are retrieved by configuring the children property in JSON; its structure is the same as the
structure of the jobs property, but it must additionally define placeholders.
In the UI, you just create a new endpoint and mark it as a Child Job of the parent job of your choice. Any placeholders,
e.g., variables that will be set from the parent object, should be enclosed in curly braces, e.g., {campaign_id}.
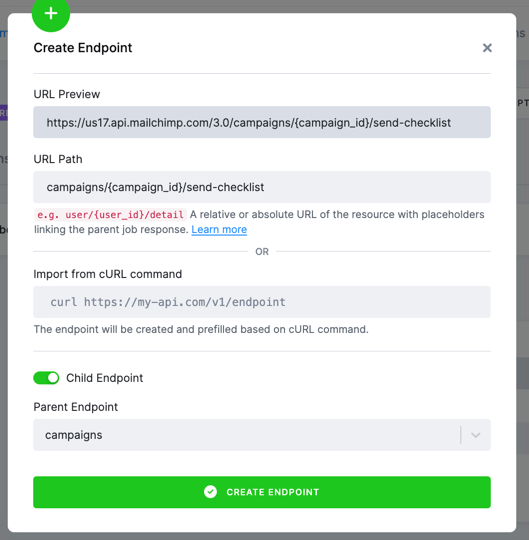
Once the endpoint is created, the Placeholders section will be prefilled for you. We will set the Response Path value to id,
since we want to use the id property from the parent response to replace the {campaign_id} placeholder in the child endpoint.
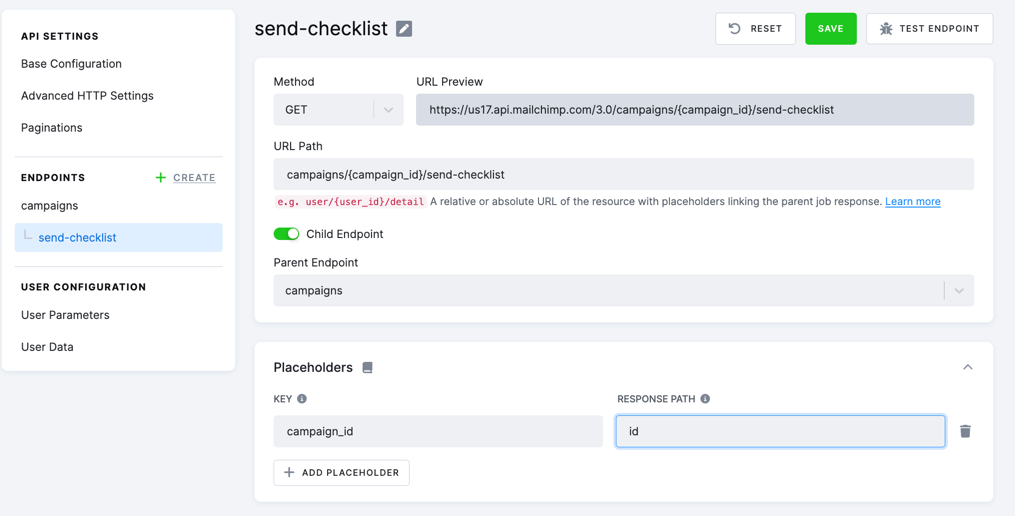
Now, you can test the endpoint as in previous examples.
The Mapping.Data Selector (aka dataField) property must refer to an array, i.e., items or _links in our case
(see the documentation).
When you look at the debug log, you will also see that the connector is making all the parent requests:

The resulting underlying JSON will look like this:
"jobs": [
{
"endpoint": "campaigns",
"dataField": "campaigns",
"children": [
{
"endpoint": "campaigns/{campaign_id}/send-checklist",
"dataField": "items",
"placeholders": {
"campaign_id": "id"
}
}
]
}
]The children are executed for each element retrieved from the parent endpoint, i.e., for each campaign.
The placeholders setting connects the placeholders used in the endpoint property with
the data in the actual parent response.
That means that the campaign_id placeholder in the campaigns/{campaign_id}/send-checklist endpoint
will be replaced by the id property of the JSON response:
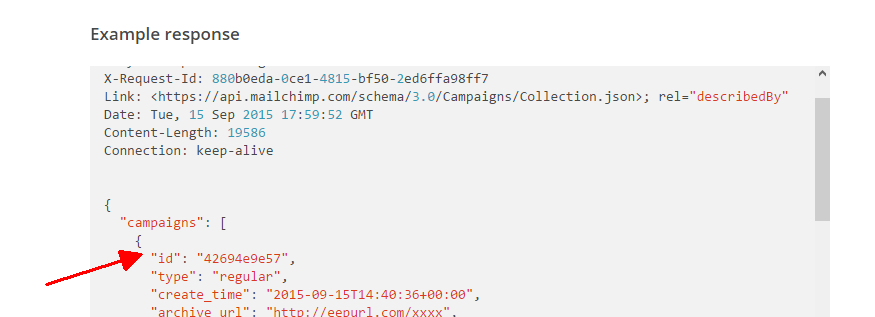
Also, note that the placeholder name is completely arbitrary (i.e., it is just a coincidence that
it is also named campaign_id in the Mailchimp documentation). Therefore, the following configuration is
also valid:
{
"parameters": {
"api": {
"baseUrl": "https://us13.api.mailchimp.com/3.0/",
"authentication": {
"type": "basic"
},
"pagination": {
"method": "offset",
"offsetParam": "offset",
"limitParam": "count",
"limit": 1
}
},
"config": {
"debug": true,
"username": "dummy",
"#password": "c40xxxxxxxxxxxxxxxxxxxxxxxxxxxxx-us13",
"outputBucket": "ge-tutorial",
"jobs": [
{
"endpoint": "campaigns",
"dataField": "campaigns",
"children": [
{
"endpoint": "campaigns/{cid}/send-checklist",
"dataField": "items",
"placeholders": {
"cid": "id"
}
}
]
}
]
}
}
}Running the above configuration gives you a new table named, for example,
in.c-ge-tutorial.campaigns__campaign_id__send-checklist. The table
contains messages from campaign checking. You will see something like this:
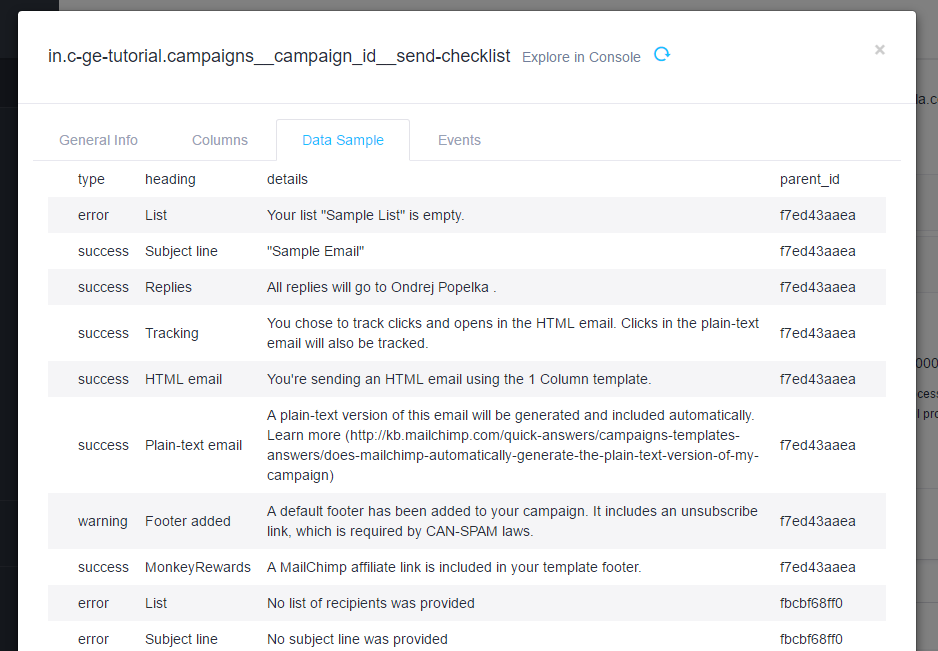
Note that apart from the API response properties type, heading, and details, an additional field,
parent_id, was added. It contains the value of the placeholder (campaign_id) for the particular
request. So, to join the two tables together in SQL, you would use the join condition:
campaigns.id=campaigns__campaign_id__send-checklist.parent_id
However, you have to remember what table the parent_id column refers to.
Multiple Jobs
You have probably noticed that the jobs and children properties are arrays. It means that you can retrieve multiple
endpoints in a single configuration. Let’s pick the campaign content sub-resource too:
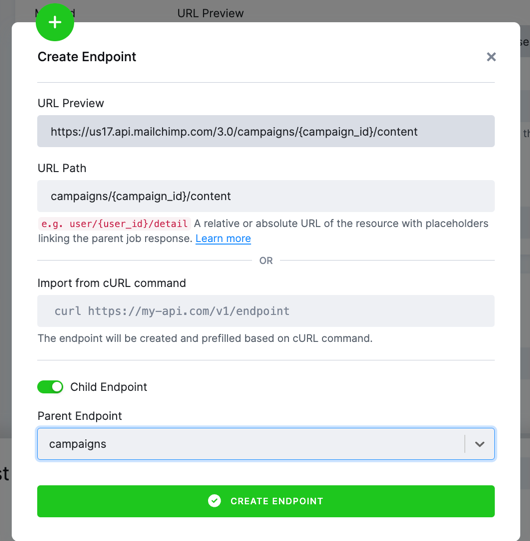
The placeholder configuration is the same, however,
the question is what to put in the Data Selector (dataField). If you examine the sample response
after running the test endpoint, it looks like this:
{
"plain_text": "** Designing...*|END:IF|*",
"html": "<!DOCTYPE html...</html>",
"_links": [
{
"rel": "parent",
"href": "https://usX.api.mailchimp.com/3.0/campaigns/42694e9e57",
"method": "GET",
"targetSchema": "https://api.mailchimp.com/schema/3.0/Campaigns/Instance.json"
},
...
]
}If you use JSON configuration with no dataField like in the above configuration and run it, you will obtain a table like this:
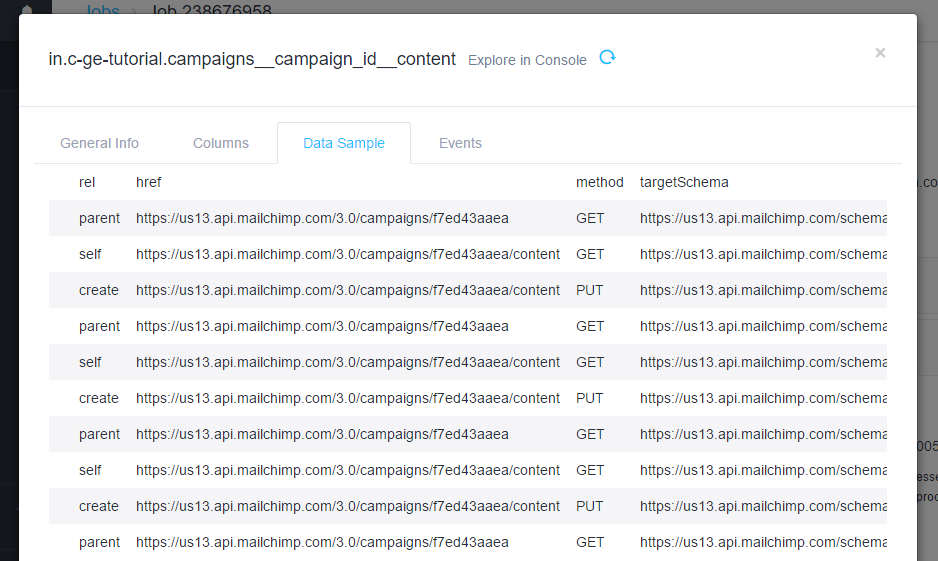
This is not what you expected. Instead of obtaining the campaign content, you
got the _links property from the response because Generic Extractor automatically
picks an array in the response. To get the entire response as a single table record, set dataField
to the path in the object. Because you want to use the
entire response, set dataField to . to start in the root.
Note: If you use the UI editor, the Data Selector (dataField) is automatically set to . by default.
The resulting JSON:
"jobs": [
{
"endpoint": "campaigns",
"dataField": "campaigns",
"children": [
{
"endpoint": "campaigns/{campaign_id}/send-checklist",
"dataField": {
"path": "items",
"delimiter": "."
},
"placeholders": {
"campaign_id": "id"
}
},
{
"endpoint": "campaigns/{campaign_id}/content",
"dataField": {
"path": ".",
"delimiter": "."
},
"placeholders": {
"campaign_id": "id"
}
}
]
}
]Running the above configuration will get you the table in.c-ge-tutorial.campaigns__campaign_id__content
with columns like plain_text, html, and others.
You will also get the table in.c-ge-tutorial.campaigns__campaign_id__content__links. It
represents the links property of the content resource. The links table contains the
JSON_parentId column, which includes a generated hash, such as
campaigns/{campaign_id}/content_1c3b951ece2a05c1239b06e99cf804c2, whose value is inserted into
the links column of the campaign content table. This is done automatically because once
you say that the entire response is supposed to be a single table row, the array _links
property will not fit into a single value of a table.
Summary
Now that you know how to extract sub-resources using child jobs, as well as resources composed directly of
properties (without an array of items), you probably think that the _links property, found all over the
MailChimp API and giving us a lot of trouble, is best to be ignored. The answer to this is
mapping, described in the tutorial’s next part.
You might also have noticed some duplicate records in the table in.c-ge-tutorial.campaigns__campaign_id__content
along the way. You’ll look into this as well.