Mapping Tutorial
In the previous part of the tutorial, you extracted the content of a MailChimp campaign. Now, it’s time to clean up the response.
This is the initial configuration:
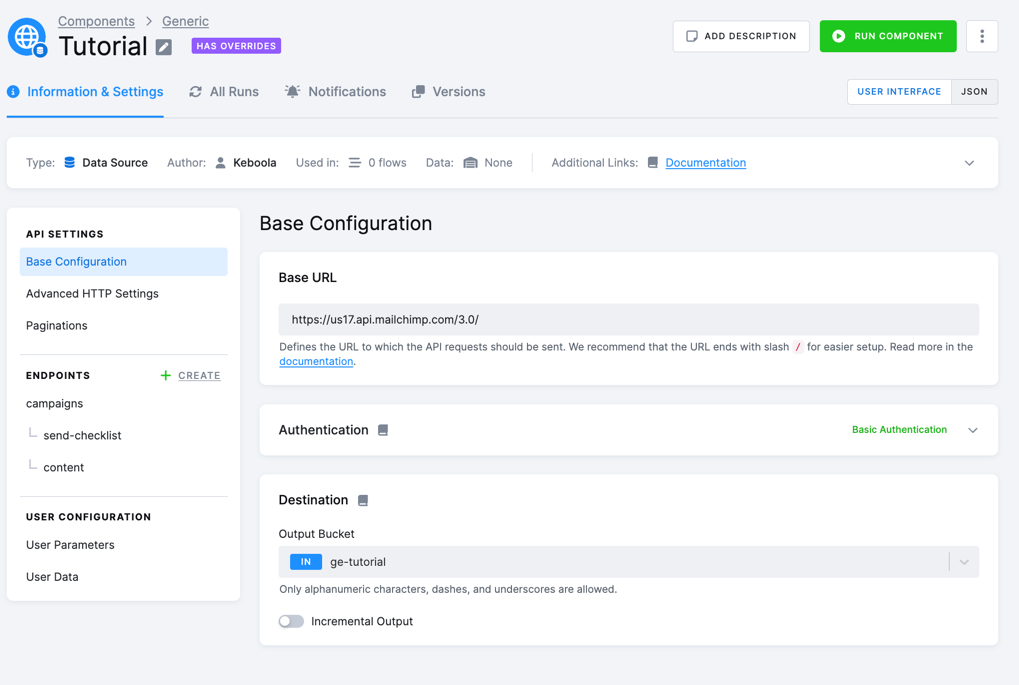
In JSON:
{
"parameters": {
"api": {
"baseUrl": "https://us13.api.mailchimp.com/3.0/",
"authentication": {
"type": "basic"
},
"pagination": {
"method": "offset",
"offsetParam": "offset",
"limitParam": "count",
"limit": 1
}
},
"config": {
"debug": true,
"username": "dummy",
"#password": "c40xxxxxxxxxxxxxxxxxxxxxxxxxxxxx-us13",
"outputBucket": "ge-tutorial",
"jobs": [
{
"endpoint": "campaigns",
"dataField": "campaigns",
"children": [
{
"endpoint": "campaigns/{campaign_id}/send-checklist",
"dataField": {
"path": "items",
"delimiter": "."
},
"placeholders": {
"campaign_id": "id"
}
},
{
"endpoint": "campaigns/{campaign_id}/content",
"dataField": {
"path": ".",
"delimiter": "."
},
"placeholders": {
"campaign_id": "id"
}
}
]
}
]
}
}
}It extracts MailChimp campaigns with the send-checklist items and campaign content.
However, you are probably not interested in some parts of the content resource. Also, the table contains duplicates.
Technical note on duplicates: If you examine the job events, you will see
the request GET /3.0/campaigns/f7ed43aaea/content?count=1&offset=0 sent. That is,
pagination applies to all API requests. Generic Extractor tries to page the
unpaged /content resource. This may ultimately lead to duplicates because the extraction of that
resource is only terminated after the resource returns the same response twice.
Mapping
A mapping defines the shape of Generic Extractor outputs. It is stored
in the config.mappings property and is identified by the resource data type.
When a resource is assigned an internal Result Name (dataType), a mapping can be created
for it. To use a mapping, first define a Result Name (dataType) in the job property.
UI
The mapping can be created in the Mapping section in the UI by clicking the Create Mapping toggle.
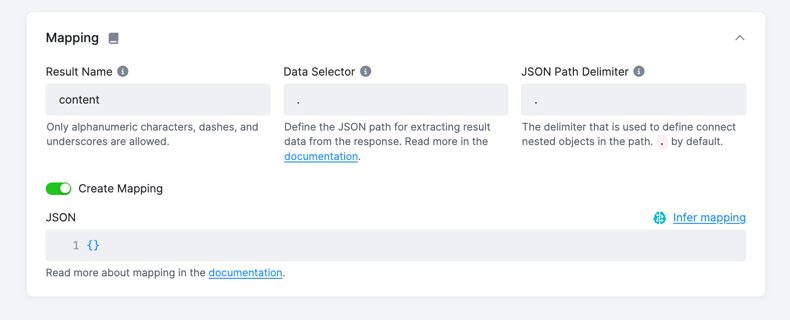
You may generate the mapping automatically by clicking theInfer Mapping button in the top right corner.
This operation will generate a mapping based on the sample response of the endpoint.
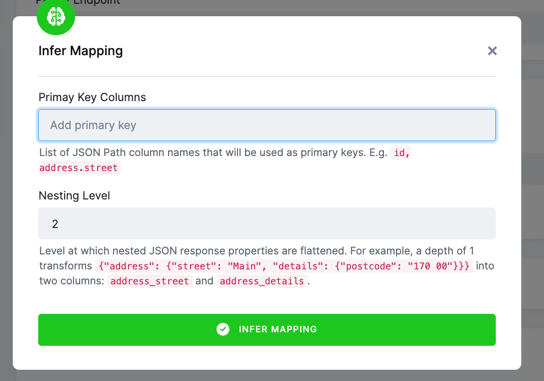
Primary key
To create a primary key, you can specify a . separated path of the elements in the response. Note: If you are mapping child jobs,
the parent keys will automatically be included.
Nesting level
Currently, the automatic detection outputs only single table mapping. You can control the nesting level by specifying
the Nesting Level property. For example, a depth of 1 transforms {"address": {"street": "Main", "details": {"postcode": "170 00"}}} into two columns:
address_street and address_details.
All elements that have ambiguous types or are beyond the specified depth are stored in a single column as JSON, e.g., with the force_type option.
For example, if you click to generate mapping on the Campaigns endpoint with level 2 and primary key id, you will get this result
(note the link between the Result Name (dataType) and mappings key):
"mappings": {"campaigns": {
"id": {
"mapping": {
"destination": "id",
"primaryKey": true
}
},
"web_id": "web_id",
"type": "type",
"create_time": "create_time",
"archive_url": "archive_url",
"long_archive_url": "long_archive_url",
"status": "status",
"emails_sent": "emails_sent",
"send_time": "send_time",
"content_type": "content_type",
"needs_block_refresh": "needs_block_refresh",
"resendable": "resendable",
"recipients.list_id": "recipients_list_id",
"recipients.list_is_active": "recipients_list_is_active",
"recipients.list_name": "recipients_list_name",
"recipients.segment_text": "recipients_segment_text",
"recipients.recipient_count": "recipients_recipient_count",
"settings.subject_line": "settings_subject_line",
"settings.title": "settings_title",
"settings.from_name": "settings_from_name",
"settings.reply_to": "settings_reply_to",
"settings.use_conversation": "settings_use_conversation",
"settings.to_name": "settings_to_name",
"settings.folder_id": "settings_folder_id",
"settings.authenticate": "settings_authenticate",
"settings.auto_footer": "settings_auto_footer",
"settings.inline_css": "settings_inline_css",
"settings.auto_tweet": "settings_auto_tweet",
"settings.fb_comments": "settings_fb_comments",
"settings.timewarp": "settings_timewarp",
"settings.template_id": "settings_template_id",
"settings.drag_and_drop": "settings_drag_and_drop",
"tracking.opens": "tracking_opens",
"tracking.html_clicks": "tracking_html_clicks",
"tracking.text_clicks": "tracking_text_clicks",
"tracking.goal_tracking": "tracking_goal_tracking",
"tracking.ecomm360": "tracking_ecomm360",
"tracking.google_analytics": "tracking_google_analytics",
"tracking.clicktale": "tracking_clicktale",
"delivery_status.enabled": "delivery_status_enabled",
"_links": {
"type": "column",
"mapping": {
"destination": "links"
},
"forceType": true
}
}}
JSON
The value of the Result Name (dataType) property is an arbitrary name. Apart from identifying
the resource type, it is also used as the output table name. If you run
the job, the content will be stored in in.c-ge-tutorial.content.
Each mapping item is identified by the property name of the resource and must contain
mapping.destination with the target column name in the output table. For example:
"mappings": {
"content": {
"plain_text": {
"mapping": {
"destination": "text"
}
}The above mapping setting defines that the
resource property plain_text will be stored in the table column text for the content data type. No other
properties of the content resource will be imported. In other words, the mapping defines
all columns of the output table.
To give an example, if you are interested in having the plain_text and html versions of the
campaign content, use a mapping like this:
"mappings": {
"content": {
"plain_text": {
"mapping": {
"destination": "text"
}
},
"html": {
"mapping": {
"destination": "html"
}
}
}
}Note that the destination value is arbitrary but must be a valid column name.
The data type name (content) must match the value of the dataType property
as defined in some jobs.
Parent Reference
The above mapping works, but it is missing the campaign ID, and you cannot
match the content to some campaign records. Therefore, you must extract the campaign ID
from the context (i.e., the job parameter). This can be done using a special user mapping.
When the mapping type is set to user, use the special prefix parent_ to refer to
a placeholder defined in the job. You can create the following mapping:
"mappings": {
"content": {
"parent_id": {
"type": "user",
"mapping": {
"destination": "campaign_id"
}
}
}
}The above configuration defines a mapping for the content data type.
In the result table named content, the column campaign_id will be created.
Its content will be the value of the id placeholder
(parent_id minus the parent_ prefix) in the respective job.
Apart from specifying what columns should be in the output table, the mapping allows you to set a column as part of a primary key. The entire configuration would then look like this:
{
"parameters": {
"api": {
"baseUrl": "https://us13.api.mailchimp.com/3.0/",
"authentication": {
"type": "basic"
},
"pagination": {
"method": "offset",
"offsetParam": "offset",
"limitParam": "count",
"limit": 10
}
},
"config": {
"debug": true,
"username": "dummy",
"#password": "c40xxxxxxxxxxxxxxxxxxxxxxxxxxxxx-us13",
"outputBucket": "ge-tutorial",
"jobs": [
{
"endpoint": "campaigns",
"dataField": "campaigns",
"children": [
{
"endpoint": "campaigns/{campaign_id}/send-checklist",
"dataField": "items",
"placeholders": {
"campaign_id": "id"
}
},
{
"endpoint": "campaigns/{campaign_id}/content",
"dataField": ".",
"dataType": "content",
"placeholders": {
"campaign_id": "id"
}
}
]
}
],
"mappings": {
"content": {
"parent_id": {
"type": "user",
"mapping": {
"destination": "campaign_id",
"primaryKey": true
}
},
"plain_text": {
"mapping": {
"destination": "text"
}
},
"html": {
"mapping": {
"destination": "html"
}
}
}
}
}
}
}Review
Now, let’s review what parts are connected and how. Note that the values in blue have been chosen arbitrarily when the configuration was created:

Summary
Mapping lets you precisely define what the extraction output will look like; it also defines primary keys.
If you do a one-time ad-hoc extraction, you may skip setting up the mapping and clean the extracted data later in Transformations. However, if you intend to use your configuration regularly or want to make it into a component, setting up a mapping is recommended.
Tips and Tricks
Key Containing a Dot Character
The key of the mapping supports dot notation to traverse into children. So, if the key contains a dot, you need to change the delimiter. See the following example:
"mappings": {
"content": {
"created.date": {
"delimiter": "/",
"type": "column",
"mapping": {
"destination": "createdDate"
}
}
}
}As you changed the delimiter from the default . to /, it’s no longer parsed as two separate keys created and date, but rather just a single key created.date.