Basic Configuration
Before configuring Generic Extractor, you should have a basic understanding of REST API and JSON format. This tutorial uses the MailChimp API, so have its documentation at hand. You also need the MailChimp API key.
Configuration
Generic Extractor configuration is written in JSON format and comprises several sections (a configuration map for navigation is available).
A user interface is available that can help you with the configuration and generate the JSON configuration for you.
Base Configuration
The first configuration part is a Base Configuration section where you can set the Base URL and Authentication method of the
API you connect to.
In our case, we will use the MailChimp API, so the Base URL will be https://us13.api.mailchimp.com/3.0/, and the Authentication method will be Basic Authentication.
Important: Make sure that the baseUrl URL ends with a slash!
In the Destination section, you can set:
- The
Output Bucketwhere the data will be stored. It will be set to the ID of the Storage Bucket Incremental Outputoption, which defines whether you want the result to overwrite the existing data or append to it. See more- Note that when using Incremental Output, you should set up the mapping.
JSON
If you switch to the JSON mode, the created configuration will translate to the api section where you set the basic properties of the API.
In the most simple case, this is the baseUrl property and authentication, as shown in this JSON snippet:
{
"api": {
"baseUrl": "https://us13.api.mailchimp.com/3.0/",
"authentication": {
"type": "basic"
}
}
}Important: Make sure that the baseUrl URL ends with a slash!
The config section describes the actual extraction. Its most important parts are the outputBucket and
jobs properties. outputBucket must be set to the ID of the Storage Bucket
where the data will be stored. If no bucket exists, it will be created.
It also contains the authentication parameters, such as username and password. Start with this
configuration section:
"config": {
"username": "dummy",
"#password": "c40xxxxxxxxxxxxxxxxxxxxxxxxxxxxx-us13",
"outputBucket": "ge-tutorial",
"incrementalOutput": false
}The password property is prefixed with the hash mark #, meaning the value will be encrypted once
you save the configuration.
Endpoint Section
Once you set up the Base Configuration, you can set up the actual endpoint to be queried.
Start by clicking the + New Endpoint button:
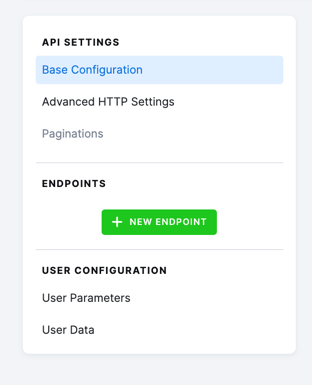
You will be asked to provide the relative endpoint URL path. In our case, we will use the campaigns endpoint.
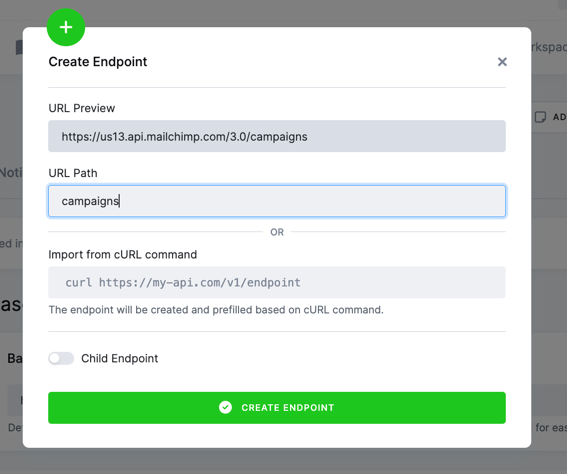
- In the URL section, you will see the resulting endpoint URL combined with the
Base URLyou set up in theBase Configurationsection.- Important: Do not start the URL with a slash. If you do so, the URL
will be absolute from the domain
https://us13.api.mailchimp.com/campaigns, which is invalid (it is missing the3.0part). An alternative would be to put/3.0/campaignsin theendpointproperty.
- Important: Do not start the URL with a slash. If you do so, the URL
will be absolute from the domain
- Alternatively, you may opt to create the endpoint using the cURL command, which is usually available in the API documentation.
Now you are getting close to a runnable configuration, and you may proceed with testing the configuration by clicking the TEST ENDPOINT button:
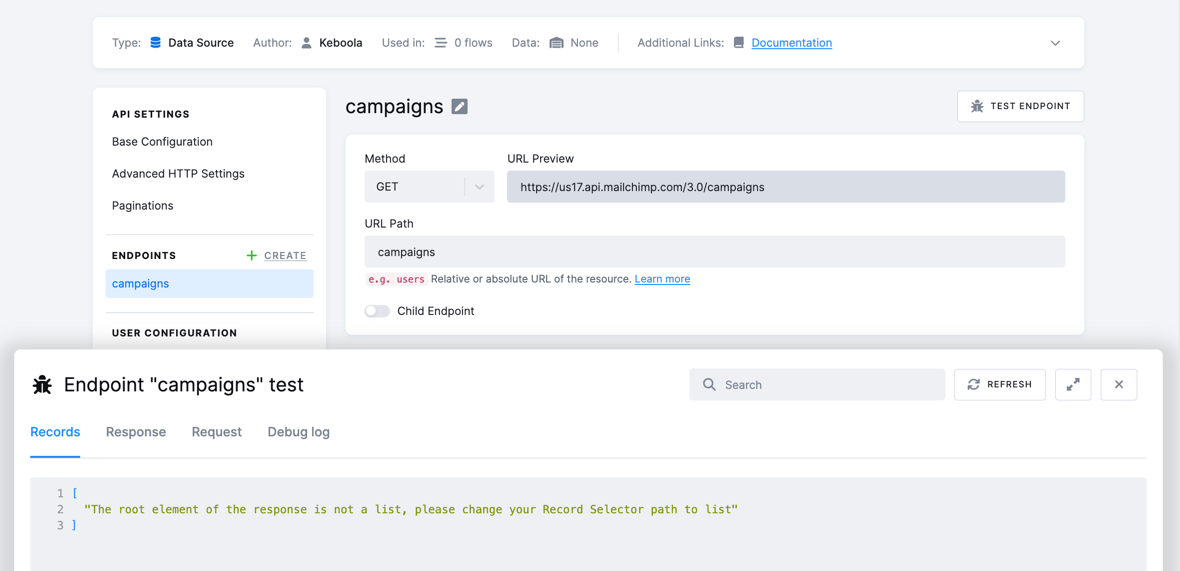
In the test endpoint popup, you will see the following sections:
Records: The actual data that will be used for parsing.Response: The response from the API. It includes headers, status code, and response body in thedataproperty.Request: The request that has been sent to the API.Debug log: A log outputted by the component for debugging purposes.
In the Records section, you will now see the following:
[
"The root element of the response is not a list; please change your Data Selector path to list"
]
Also, if you try to run this configuration, you will get an error similar to this:
The response contains more than one array! Use the 'dataField' parameter to specify a key to the data array.
(endpoint: campaigns, arrays in the response root: campaigns, _links)
That means that the extractor got the response but cannot automatically process it. The Data Selector path doesn’t point to an array.
Examine the data attribute of the response, and you will see the following objects: campaigns, total_items, and _links:
{
"campaigns": [
{
"id": "42694e9e57",
"type": "regular",
...
},
{
"id": "f6276207cc",
"type": "regular",
...
}
],
"total_items": 2,
"_links": [
{
"rel": "parent",
"href": "https://usX.api.mailchimp.com/3.0/",
"method": "GET",
"targetSchema": "https://api.mailchimp.com/schema/3.0/Root.json"
},
{
"rel": "self",
"href": "https://usX.api.mailchimp.com/3.0/campaigns",
"method": "GET",
"targetSchema": "https://api.mailchimp.com/schema/3.0/Campaigns/Collection.json",
"schema": "https://api.mailchimp.com/schema/3.0/CollectionLinks/Campaigns.json"
}
]
}Generic Extractor expects the response to be an array of items. If it receives an object, it
searches its properties to find an array. Finding multiple arrays will be confusing because it is unclear which array you want.
To fix this, change the Data Selector parameter (aka dataField) to value campaigns to point to the array of items you want to extract.
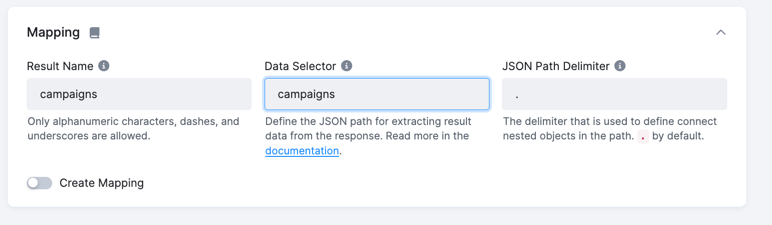
Now, run the configuration by clicking the Run button and go to the job details to see what happened:
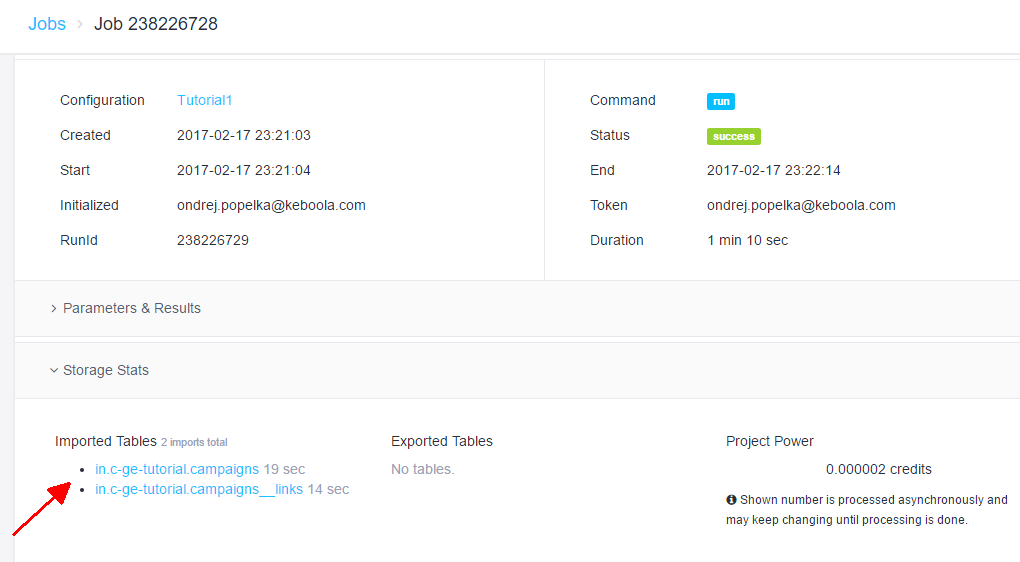
The extraction produced two tables. The in.c-ge-tutorial.campaigns table contains all the
fields of a campaign and as many rows as you have campaigns.
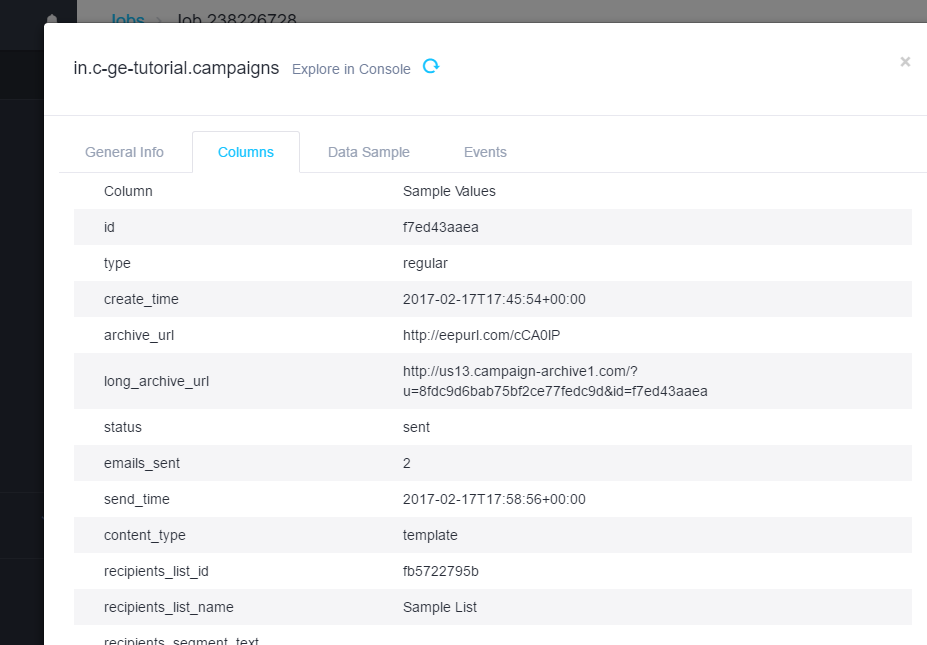
The table in.c-ge-tutorial.campaigns__links contains the contents of the _links property.
Because the _links property is a nested array within a single campaign object, it cannot be easily
represented in a single column of the campaigns table. Generic Extractor, therefore, replaces the column
value with a generated key, for example, campaigns_75d5b14d79d034cd07a9d95d5f0ca5bd, and automatically
creates a new table that has the column JSON_parentId with that value so that you can join the tables together.
Final JSON Configuration
The main parts of the configuration and their nesting are shown in the following schema:

The resulting JSON configuration will look like this:
{
"parameters": {
"api": {
"baseUrl": "https://us13.api.mailchimp.com/3.0/",
"authentication": {
"type": "basic"
}
}
"config": {
"username": "dummy",
"#password": "c40xxxxxxxxxxxxxxxxxxxxxxxxxxxxx-us13",
"outputBucket": "ge-tutorial",
"jobs": [
{
"endpoint": "campaigns",
"dataField": {
"path": "campaigns",
"delimiter": "."
}
}
]
}
}
}Important: It may seem confusing that the endpoint and dataField properties are set to campaigns.
This is just a coincidence; the endpoint property refers to the campaigns in the resource URL, and
the dataField refers to the campaigns property in the JSON retrieved as the API response.
Summary
The above tutorial demonstrates a very basic configuration of Generic Extractor. The extractor is capable of doing much more; see other parts of this tutorial for an explanation of pagination, jobs and mapping:
- Pagination — breaks a result with many items into separate pages.
- Jobs — describe the API endpoints (resources) to be extracted.
- Mapping — describes how the JSON response is converted into CSV files that will be imported into Storage.